在B端系统中,导出能是用户日常工作中不可或缺的功能。用户经常需要将业务数据、统计信息等导出为Excel表格,用于数据分析、报表生成或存档。随着系统的推广使用,数据量不断增长,如何高效、稳定地实现大数据量的Excel导出成为了我们面临的重要挑战。
1.1 初始方案:前端直接导出实现
在系统开发初期,考虑到数据量相对较小(通常在几千条以内),我们选择了前端直接导出的方案。这种方案实现简单,无需后端特殊处理,用户体验也较为流畅。
核心实现逻辑如下:
- 一次性获取所有数据:通过API请求获取符合条件的所有数据(设置较大的pageSize)
- 前端数据处理:对获取的数据进行格式化和转换
- 调用Excel生成库:使用专门的前端库将数据转换为Excel文件
- 触发浏览器下载:将生成的Excel文件提供给用户下载
具体代码实现:
oldExportToExcel() { let _this = this _this.exportLoading = true
const url = _this.jUrl.list request.get(url, { ..._this.queryParam, pageNo: 1, pageSize: 10000, }).then(response => { if (response.success && response.result && response.result.records) { const data = this.formatExportData(response.result.records) try { const { export_json_to_excel } = require('@/vendor/Export2Excel') export_json_to_excel( _this.tHeader, data, _this.title, [] ) } catch (error) { console.error('导出失败:', error) this.$message.error('导出失败,请重试') } finally { _this.exportLoading = false } } else { _this.exportLoading = false this.$message.warning('暂无数据可导出') } }).catch(error => { console.error('数据获取失败:', error) _this.exportLoading = false this.$message.error('数据获取失败,请重试') })}formatExportData(dataList) { return dataList.map(item => { return { id: item.id || '', name: item.name || '', contact: item.phone || '', email: item.email || '', businessField: item.positionName || '', status: item.statusName || '', createTime: item.createTime || '' } })}
1.2 Export2Excel库的实现原理
在前端导出方案中,我们使用了@/vendor/Export2Excel
核心依赖:
- xlsx.js:负责将数据转换为Excel文件格式
- file-saver.js:处理文件下载功能
- Blob.js:提供二进制大对象处理能力,确保在不同浏览器中兼容性
主要实现流程:
- 数据转换:将JSON格式数据转换为Excel工作表(worksheet)结构
- 样式设置:为表头和内容设置字体、颜色、对齐方式等样式
- 列宽自适应:根据内容长度自动计算并设置列宽,特别处理中文字符
- 合并单元格:支持复杂的单元格合并需求
- 文件生成:将工作表打包成完整的工作簿(workbook)并生成二进制数据
- 触发下载:使用Blob和file-saver实现Excel文件的下载
核心函数:
function format_json(filterVal, jsonData) { }export function export_json_to_excel(header, data, filename, merges) { }export function s2ab(s) { }
1.3 性能瓶颈:小数据方案的局限性
随着系统用户量的增长和数据的累积,当初始方案面对大量数据时(特别是当需要导出数千甚至数万人的候选人信息时),逐渐暴露出严重的性能问题:
- 页面卡顿甚至崩溃:大量数据处理会阻塞JavaScript主线程,导致UI无响应
- 内存占用过高:一次性加载和处理大量数据会导致浏览器内存急剧上升,在低配置设备上尤为明显
- 请求超时:单次请求数据量过大容易导致服务器超时,特别是在网络环境不稳定的情况下
- 用户体验差:用户需要长时间等待,没有任何进度反馈,无法判断导出是否成功或何时完成
这些问题促使我们必须重新思考和优化Excel导出方案,以满足日益增长的数据量需求和用户体验要求。
二、解决方案:前端优化与后端导出的智能分流
面对大数据量导出的挑战,我们采取了"双管齐下"的策略:一方面对前端导出进行性能优化,另一方面引入后端导出作为补充方案。通过智能分流机制,根据数据量和使用场景自动选择最适合的导出方式。
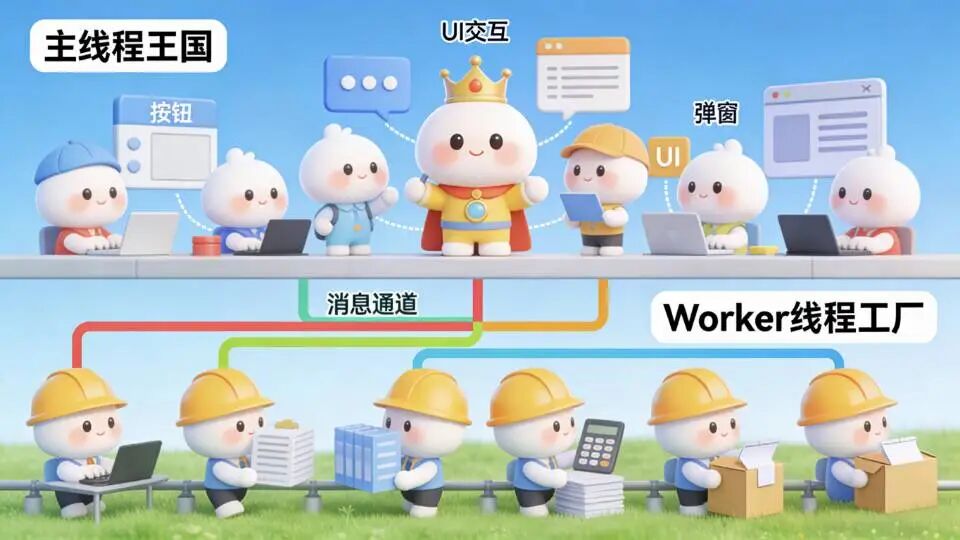
2.1 前端优化:Web Worker助力大数据处理
对于中等规模的数据量(通常在1万条以内),我们对前端导出流程进行了全面重构,具体webWorker实现可查看上一篇文章大数据处理的前端性能优化方案
核心优化思路如下:
- 数据分片获取:将大数据量请求拆分为多个小批量请求,避免单次请求数据过大
- 并行处理:使用Web Worker在后台线程并行处理数据,不阻塞主线程
- 渐进式数据合并:逐步收集和合并数据,避免一次性加载全部数据到内存
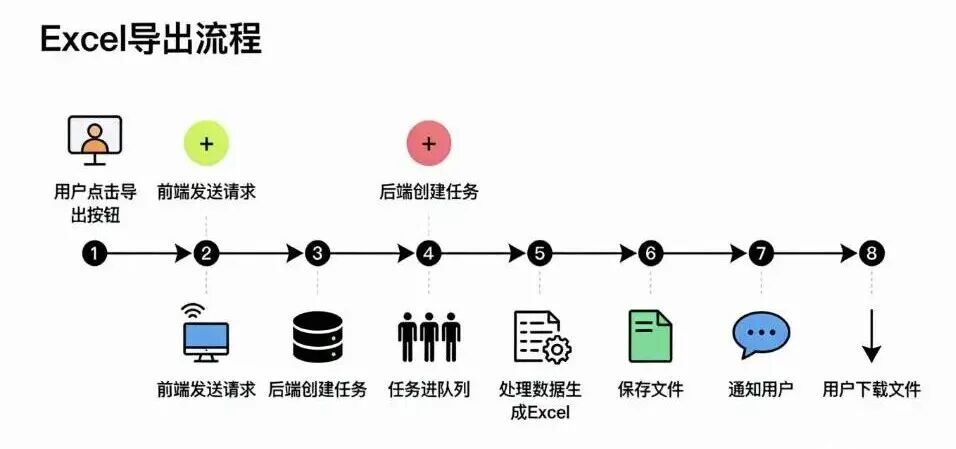
2.2 后端导出:超大批量数据的终极解决方案
对于超大批量数据(通常在10万条以上),我们引入了后端导出方案,其核心实现包括:
- 异步任务处理:将导出任务提交到后台队列,通过异步方式处理
- 服务器端生成:在服务器端直接生成Excel文件,避免前端资源消耗
- 文件存储与下载:生成的文件存储在服务器,提供下载链接给用户
- 任务状态通知:通过WebSocket或定时轮询,向用户反馈导出进度和结果
后端导出实现流程图:
2.2 Web Worker实现
下面是我们的Worker.js核心实现代码:
self.onmessage = function (e) { let data = JSON.parse(JSON.stringify(e.data)) self.url = data.url self.headers = data.header self.params = data.params self.startPage = data.startPage self.endPage = data.endPage let paramsArray = [] Object.keys(self.params).forEach((key) => paramsArray.push(key + '=' + self.params[key]) ) if (self.url.search(/\?/) === -1) { self.url += '?' + paramsArray.join('&') } else { self.url += '&' + paramsArray.join('&') } self.fetchRequest = async (pageNo) => { let url = `${self.url}&pageNo=${pageNo}` return new Promise((resolve, reject) => { fetch(url, { method: 'get', headers: self.headers, }) .then((res) => res.json()) .then((res) => { resolve(res) }) .catch((err) => { reject(err) }) }) } self.getList = async () => { let list = [] for (let i = self.startPage; i <= self.endPage; i++) { let { success, result } = await self.fetchRequest(i) if (success && result && result.records && result.records.length) { list = list.concat(result.records) } } self.postMessage({ list }) } self.getList()}
2.3 主线程实现
在主线程中,我们实现了智能的数据获取策略选择和Worker管理:
self.onmessage = function (e) { let data = JSON.parse(JSON.stringify(e.data)) self.url = data.url self.headers = data.header self.params = data.params self.startPage = data.startPage self.endPage = data.endPage let paramsArray = [] Object.keys(self.params).forEach((key) => paramsArray.push(key + '=' + self.params[key]) ) if (self.url.search(/\?/) === -1) { self.url += '?' + paramsArray.join('&') } else { self.url += '&' + paramsArray.join('&') } self.fetchRequest = async (pageNo) => { let url = `${self.url}&pageNo=${pageNo}` return new Promise((resolve, reject) => { fetch(url, { method: 'get', headers: self.headers, }) .then((res) => res.json()) .then((res) => { resolve(res) }) .catch((err) => { reject(err) }) }) } self.getList = async () => { let list = [] for (let i = self.startPage; i <= self.endPage; i++) { let { success, result } = await self.fetchRequest(i) if (success && result && result.records && result.records.length) { list = list.concat(result.records) } } self.postMessage({ list }) } self.getList()}
exportFile({ title, tHeader, filterVal, merges = [], idsType = 'string', queryIds = [],}) { let _this = this let ids = this.selectedRowKeys if (queryIds.length > 0) { ids = queryIds } require.ensure([], async () => { _this.exportFilterVal = filterVal _this.exportMerges = merges _this.exportTitle = title _this.exportTHeader = tHeader let list = [] _this.exportLoading = true if (ids && ids.length) { const url = _this.jUrl.list const data = await request.get(url, { id: idsType === 'string' ? ids.join(',') : ids, pageNo: 1, pageSize: ids.length + 10, column: 'createTime', order: 'desc', }) list = data.result ? data.result.records ? data.result.records : data.result : [] _this.exportByList(list) } else { let currentPage = Math.ceil(_this.pagination.total / 1000) let totalPage = currentPage > 100 ? 100 : currentPage if (totalPage >= 10) { _this.excelDataInfoByworker(totalPage) } else { for (let i = 0; i < totalPage; i++) { const temp = await _this.excelDataInfo(i + 1, 1000) list = list.concat(temp) } _this.exportByList(list) } } })},excelDataInfoByworker(totalPage) { let _this = this this.exportWorkerIndex = 0 this.exportList = [] let url = process.env.VUE_APP_API_BASE_URL + '/' + this.jUrl.list let header = this.tokenHeader let params = { url, header, params: Object.assign( this.queryParam, { pageSize: 1000, }, this.otherQueryParams ), } let pages = Math.floor(totalPage / 10) for (let i = 0; i < 10; i++) { let worker1 = new Worker(new URL('./worker.js', import.meta.url)) let params1 = JSON.parse(JSON.stringify(params)) params1.startPage = i * pages + 1 if (i == 9) { params1.endPage = totalPage } else { params1.endPage = (i + 1) * pages } worker1.postMessage(params1) worker1.onmessage = (e) => { _this.exportWorkerIndex++ if (e.data && e.data.list && e.data.list.length > 0) { _this.exportList = _this.exportList.concat(e.data.list) } if (_this.exportWorkerIndex == 10) { _this.exportByList(_this.exportList) } worker1.terminate() } }}
三、Excel生成与下载实现
完成数据获取后,我们使用xlsx库生成Excel文件并提供下载功能:
export function format_json(filterVal, jsonData) { return jsonData.map((v) => filterVal.map((j) => { const jAarr = j.split('.') const jLength = jAarr.length if (v[jAarr[0]] || v[jAarr[0]] == 0) { if (jLength === 1) { return String(v[jAarr[0]]) } else if (jLength === 2) { if (v[jAarr[0]][jAarr[1]]) { return String(v[jAarr[0]][jAarr[1]]) } else { return '' } } } else { return '' } }) )}export function export_json_to_excel(header, data, filename, merges) { filename = filename || 'excel-list' data = [...data] data.unshift(header) var ws_name = 'Sheet1' var wb = new Workbook(), ws = sheet_from_array_of_arrays(data) for (var i = 0; i < header.length; i++) { var str = String.fromCharCode(65 + i) var head = str + '1' if (ws[head]) { ws[head].s = { font: { sz: 12, bold: true, color: { rgb: '000000' } }, alignment: { vertical: 'center', horizontal: 'center' }, fill: { bgColor: { indexed: 64 }, fgColor: { rgb: 'CCCCCC' } }, } } for (let j = 2; j < data.length; j++) { var body = str + j if (str == 'D') { if (ws[body]) { ws[body].s = { font: { sz: 12 }, alignment: { vertical: 'center', horizontal: 'left', wrapText: 1, indent: 0, }, } } } else { if (ws[body]) { ws[body].s = { font: { sz: 12 }, alignment: { vertical: 'center', horizontal: 'center', wrapText: 1, indent: 0, }, } } } } } if (merges) { ws['!merges'] = merges } let autoWidth = true if (autoWidth) { const colWidth = data.map((row) => row.map((val) => { if (val == null) { return { wch: 10, } } else if (val.toString().charCodeAt(0) > 255) { return { wch: val.toString().length * 2, } } else { return { wch: val.toString().length, } } }) ) let result = colWidth[0] for (let i = 1; i < colWidth.length; i++) { for (let j = 0; j < colWidth[i].length; j++) { if (result[j]['wch'] < colWidth[i][j]['wch']) { result[j]['wch'] = colWidth[i][j]['wch'] } } } result.forEach((resultItem) => { if (resultItem.wch > 150) { resultItem.wch = 150 } }) ws['!cols'] = result } wb.SheetNames.push(ws_name) wb.Sheets[ws_name] = ws var wbout = XLSX.write(wb, { bookType: 'xlsx', bookSST: false, type: 'binary', }) saveAs( new Blob([s2ab(wbout)], { type: 'application/octet-stream', }), filename + '.xlsx' )}export function s2ab(s) { var buf = new ArrayBuffer(s.length) var view = new Uint8Array(buf) for (var i = 0; i != s.length; ++i) view[i] = s.charCodeAt(i) & 0xff return buf}
四、实现效果
通过这些优化,我们成功解决了大数据量导出的问题,实现了以下效果:
- 页面不再卡顿:Web Worker在后台处理数据,主线程保持响应
- 内存占用优化:分批加载和处理数据,避免一次性加载全部数据
- 导出速度提升:多线程并行处理大幅提升了大数据量的导出速度
- 稳定性增强:避免了因数据量过大导致的浏览器崩溃问题
五、功能完善与后续优化
随着系统的使用,我们还进行了以下完善:
5.1 导出前数据处理
增加了数据预处理功能,确保导出数据的准确性和一致性:
async excelDataInfo(pageNo, pageSize) { let queryParam = this.handleQueryParam() const obj = Object.assign( queryParam, { pageNo, pageSize, }, this.otherQueryParams ) const url = this.jUrl.list const data = await request.get(url, obj) let result = [] if (data && data.result && data.result.records) { data.result.records.forEach((item) => { if (item.age) { item.age = String(item.age) } if (item.isLongValid == '1') { item.certificateEndDate = '长期' } }) result = data.result.records } return result}
5.2 用户体验优化
添加了加载状态提示,让用户了解导出进度:
exportByList(list) { console.log('导出', list.length) try { const { export_json_to_excel, format_json, } = require('@/vendor/Export2Excel') const data = format_json(this.exportFilterVal, list) export_json_to_excel( this.exportTHeader, data, this.exportTitle, this.exportMerges ) setTimeout(() => { this.exportLoading = false }, 1500) } catch (error) { console.log(error) }}
5.3 未来优化方向
尽管我们已经取得了显著的优化效果,但仍有改进空间:
- Worker池管理:实现Worker池机制,避免频繁创建和销毁Worker实例
- 进度反馈增强:提供更精确的导出进度反馈,如百分比显示
- 流式处理:对于超大批量数据,实现真正的流式处理,进一步降低内存占用
- 错误处理增强:完善Worker中的错误处理机制,提供更好的容错能力
- 导出队列:实现导出任务队列,避免同时进行多个大数据量导出操作
六、前端导出与后端导出:场景选择与最佳实践、
在我们的项目中,我们同时使用了前端导出和后端导出两种方案,它们各自有不同的适用场景和优势。下面是对两种方案的详细对比和选择建议:
6.1 前端导出的适用场景
前端导出(包括优化后的Web Worker方案)适用于以下情况:
- 数据量适中:通常适用于1万条以内的数据导出
- 实时性要求高:用户需要立即获取导出结果
- 个性化需求强:需要根据用户操作动态生成导出内容
- 网络环境良好:网络带宽充足,延迟较低
- 服务器资源紧张:希望减轻服务器负担
前端导出的优势:
- 实现简单,无需后端复杂处理
- 响应迅速,用户无需长时间等待
- 交互灵活,可以根据用户选择动态调整导出内容
6.2 后端导出的适用场景
后端导出适用于以下情况:
- 超大批量数据:通常适用于10万条以上的数据导出
- 数据处理复杂:需要进行复杂的数据计算、汇总或跨系统数据整合
- 格式要求严格:需要严格按照特定格式或规范生成Excel文件
- 稳定性要求高:不希望因前端环境差异导致导出失败
- 离线处理需求:用户可以提交任务后离开,稍后再来获取结果
后端导出的优势:
- 不受前端资源限制,可以处理超大批量数据
- 稳定性更高,不受浏览器和设备性能影响
- 可以实现更复杂的数据处理和格式定制
- 支持异步处理和任务排队机制
6.3 智能分流策略
在实际应用中,我们采用了智能分流策略,根据不同情况自动选择最合适的导出方式:
- 小数据量(<5000条):直接使用前端简单导出
- 中等数据量(5000-10000条):使用Web Worker优化的前端导出
- 大数据量(>10000条):自动切换到后端导出方案
6.4 优化经验总结
通过这次Excel导出功能的优化过程,我们总结出以下经验:
- 分析问题根源:面对性能瓶颈,首先要深入分析问题的根本原因,而不是简单地增加硬件资源
- 技术选型要匹配场景:不同的技术有不同的适用场景,要根据实际需求选择最合适的方案
- 组合多种技术方案:单一技术往往难以应对复杂场景,组合多种技术可以达到最佳效果
- 用户体验优先:无论采用哪种方案,都要确保用户有良好的体验,如进度反馈、错误处理等
- 持续监控和优化:系统上线后,要持续监控性能表现,并根据实际运行情况进行优化
6.5 结语
Excel导出看似简单,但在大数据量场景下却面临诸多挑战。通过前端优化与后端导出的智能结合,我们成功解决了这一难题,为用户提供了稳定、高效的数据导出体验。
在Web应用开发中,面对类似的性能挑战,我们应该保持开放的思维,综合运用各种技术手段,以用户体验为中心,不断优化和完善系统功能。只有这样,才能打造出既功能强大又用户友好的高质量Web应用。
阅读原文:原文链接
该文章在 2025/12/11 8:52:07 编辑过






 400 186 1886
400 186 1886