Sora是一个以视频生成为核心的多能力模型,具备以下能力:
文/图生成视频
视频生成视频
1分钟超长高质量视频生成
视频裂变多视角生成
准工业级数字孪生游戏/科幻片等特效,物理引擎能力
1.Sora 与 Runway Gen2、Pika 等能力差异对比
| 能力项 | OpenAl Sora | 其它模型 |
|---|
| 视频时长 | 60 秒 | 最多十几秒 |
| 视频长宽比 | 1920x1080 与 1080x1920 之间任意尺寸 | 固定尺寸, 如 16:9,9:16,1:1 等 |
| 视频清晰度 | 1080P | upscale 之后达到 4K |
| 文本生成视频 | 支持 | 支持 |
| 图片生成视频 | 支持 | 支持 |
| 视频生成视频 | 支持 | 支持 |
| 多个视频链接 | 支持 | 不支持 |
| 文本编辑视频 | 支持 | 支持 |
| 扩展视频 | 向前 / 向后扩展 | 仅支持向后扩展 |
| 视频连接 | 支持 | 不支持 |
| 真实世界模拟 | 支持 | 支持 |
| 运动相机模拟 | 强 | 弱 |
| 依赖关系进行建模 | 强 | 弱 |
| 影响世界状态 (世界交互) | 强 | 弱 |
| 人工过程 (数字世界) 模拟 | 支持 | 不支持 |
视频清晰度,OpenAI Sora 默认是 1080P,而且其它平台大多数默认的清晰度也都是 1080P 以下,只是在经过 upscale 等操作之后可以达到更清晰的水平。
Sora 开箱即用生成60s 的时长视频,其中视频连接、数字世界模拟、影响世界状态(世界交互)、运动相机模拟等都是此前视频平台或者工具中不具备的。
OpenAI Sora 模型还可以直接生成图片,它是一个以视频生成为核心的多能力模型。
2. Sora技术突破点
sora 是一个以 latent、transformer、diffusion 为三个关键点的模型。
官网案例展示

世界模型和物理引擎是虚拟现实(VR)和计算机图形学中的两个关键概念。世界模型是描述虚拟环境的框架,包括场景、对象、光照等元素,用于呈现虚拟世界的外观和感觉。物理引擎则是用于模拟和计算物体之间的物理运动和互动,如重力、碰撞、摩擦等。简而言之,世界模型是虚拟环境的静态描述,而物理引擎则负责模拟虚拟环境中物体的动态行为。它们共同作用于虚拟现实技术中,为用户提供沉浸式的体验。
世界模型要求更高,这包括对复杂场景和物理效果的处理能力、提高在新环境中的泛化能力、以及更好地利用先验知识进行实时推理、预测和决策等。虽然 Sora 已经能够生成较为准确的视频内容,但当场景中涉及到多个物体的交互或复杂的物理运动时,Sora 可能会出现失误或偏差。其次 Sora 目前主要依赖于大量的训练数据来学习视频的生成规律,但这种方式可能限制了其在新环境中的泛化能力和实时决策能力。这也是目前 Sora 并非一个世界模型的原因
模拟器实例化了两种精美的 3D 资产:具有不同装饰的海盗船。 Sora 必须在其潜在空间中隐式地解决文本到 3D 的问题。
3D 对象在航行并避开彼此路径时始终保持动画效果。
咖啡的流体动力学,甚至是船舶周围形成的泡沫。流体模拟是计算机图形学的一个完整子领域,传统上需要非常复杂的算法和方程。
照片写实主义,几乎就像光线追踪渲染一样。
模拟器考虑到杯子与海洋相比尺寸较小,并应用移轴摄影来营造 “微小” 的氛围。
场景的语义在现实世界中并不存在,但引擎仍然实现了我们期望的正确物理规则。
提示词:“两艘海盗船在一杯咖啡内航行时互相战斗的逼真特写视频。”

提示词:一位时尚的女人走在东京的街道上,街道上到处都是温暖的发光霓虹灯和动画城市标志。她身穿黑色皮夹克,红色长裙,黑色靴子,背着一个黑色钱包。她戴着墨镜,涂着红色口红。她自信而随意地走路。街道潮湿而反光,营造出五颜六色的灯光的镜面效果。许多行人四处走动

视频链接:https://live.csdn.net/v/364231
自主创建多个视角的视频
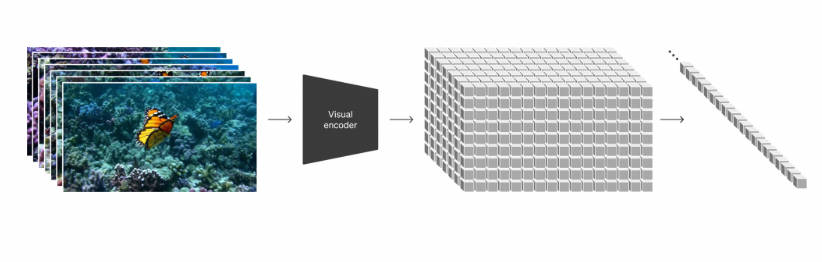
从 Sora 模型的技术报告中,我们可以看到 Sora 模型的实现,是建立在 OpenAI 一系列坚实的历史技术工作的沉淀基础上的包括不限于视觉理解(Clip),Transformers 模型和大模型的涌现(ChatGPT),Video Caption(DALL·E 3)
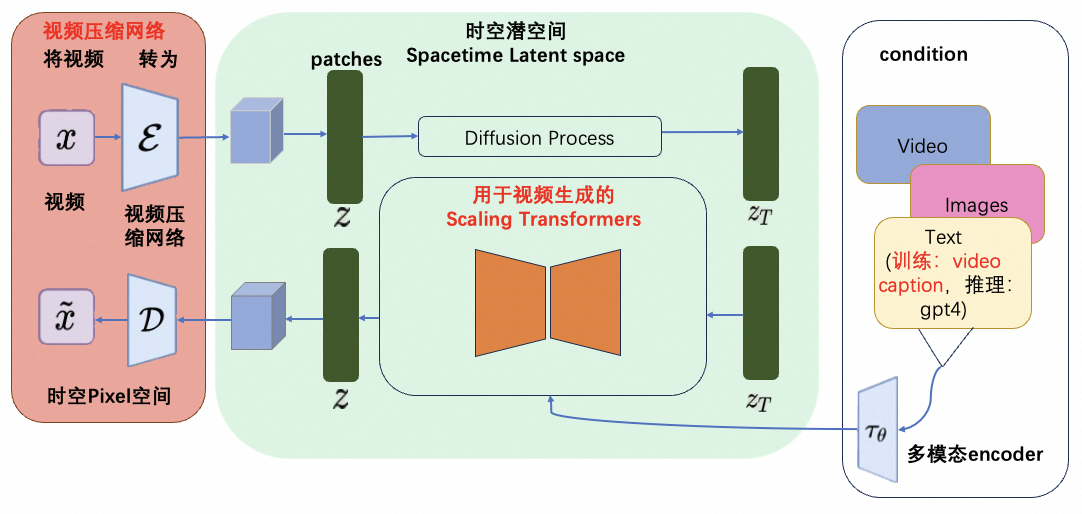
2.1 核心点1:视频压缩网络
patches 是从大语言模型中获得的灵感,大语言模型范式的成功部分得益于使用优雅统一各种文本模态(代码、数学和各种自然语言)的 token。大语言模型拥有文本 token,而 Sora 拥有视觉分块(patches)。OpenAI 在之前的 Clip 等工作中,充分实践了分块是视觉数据模型的一种有效表示(参考论文:An image is worth 16x16 words: Transformers for image recognition at scale.)这一技术路线。而视频压缩网络的工作就是将高维度的视频数据转换为 patches,首先将视频压缩到一个低纬的 latent space,然后分解为 spacetime patches。
难点:视频压缩网络类比于 latent diffusion model 中的 VAE,但是压缩率是多少,如何保证视频特征被更好地保留,还需要进一步的研究。
给定输入的噪声块 + 文本 prompt,它被训练来预测原始的 “干净” 分块。重要的是,Sora 是一个 Scaling Transformers。Transformers 在大语言模型上展示了显著的扩展性,
难点:能够 scaling up 的 transformer 如何训练出来,对第一步的 patches 进行有效训练,可能包括的难点有 long context(长达 1 分钟的视频)的支持、期间 error accumulation 如何保证比较低,视频中实体的高质量和一致性,video condition,image condition,text condition 的多模态支持等。
2.3 核心点3:Video recaption
视频摘要 / 视频字母生成属于多模态学习下的一个子任务,大体目标就是根据视频内容给出一句或多句文字描述。所生成的 caption 可用于后续的视频检索等等,也可以直接帮助智能体或者有视觉障碍的人理解现实情况。通过这样的高质量的训练数据,保障了文本(prompt)和视频数据之间高度的 align。Sora 还使用 DALL·E 3 的 recaption技巧,即为视觉训练数据生成高度描述性的 caption,这让 Sora 能够更忠实地遵循生成视频中用户的文本指令,而且会支持长文本,这个应该是 OpenAI 独有的优势。在生成阶段,Sora 会基于 OpenAI 的 GPT 模型对于用户的 prompt 进行改写,生成高质量且具备很好描述性的高质量 prompt,再送到视频生成模型完成生成工作。caption 训练数据都匮乏:
一方面,图像常规的文本描述往往过于简单(比如 COCO 数据集),它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等。
另外一方面,目前训练文生图的图像文本对数据集(比如 LAION 数据集)都是从网页上爬取的,图像的文本描述其实就是 alt-text,但是这种文本描述很多是一些不太相关的东西,比如广告。
技术突破:训练一个 image captioner 来合成图像的 caption,合成 caption 与原始 caption 的混合比例高达 95%:5%;但是不过采用 95% 的合成长 caption 来训练,得到的模型也会 “过拟合” 到长 caption 上,如果采用常规的短 caption 来生成图像,效果可能就会变差。为了解决这个问题,OpenAI 采用 GPT-4 来 “upsample” 用户的 caption,下面展示了如何用 GPT-4 来进行这个优化,不论用户输入什么样的 caption,经过 GPT-4 优化后就得到了长 caption:
难点:这项技术并不新,难的是积累,即便是合成数据也需要大量的专业标注和评测。“大” 模型,“高” 算力,“海量” 数据
更多内容见:探索AI视频生成新纪元:文生视频Sora VS RunwayML、Pika及StableVideo——谁将引领未来:https://blog.csdn.net/sinat_39620217/article/details/136171409
3.sora存在不足



物理交互逻辑错误:Sora 有时会创造出物理上不合理的动作; Sora 模型在模拟基本物理交互,如玻璃破碎等方面,不够精确。这可能是因为模型在训练数据中缺乏足够的这类物理事件的示例,或者模型无法充分学习和理解这些复杂物理过程的底层原理
对象状态变化的不正确:在模拟如吃食物这类涉及对象状态显著变化的交互时,Sora 可能无法始终正确反映出变化。这表明模型可能在理解和预测对象状态变化的动态过程方面存在局限。
复杂场景精确性丢失:模拟多个对象和多个角色之间的复杂互动会出现超现实结果; 长时视频样本的不连贯性:在生成长时间的视频样本时,Sora 可能会产生不连贯的情节或细节,这可能是由于模型难以在长时间跨度内保持上下文的一致性 ; 对象的突然出现:视频中可能会出现对象的无缘无故出现,这表明模型在空间和时间连续性的理解上还有待提高
4.文生视频prompt优化
| 视频 | 官方提示词 | 优化 |
|---|
 | 逼真的特写视频,展示两艘海盗在一杯咖啡内航行时互相争斗的情况。 | Context:一杯啡内的微型世界。
Persona: 两艘海盗船。
Goal: 展示海盗船在咖杆内的逼真争斗场景。
Constraints:视频应突出海盗船的细节和动态,以及咖啡的纹理作为背景。
Steps:设定场景为充满咖啡的杯子,咖啡表面作为海洋。描述海盗船:两艘细致的海盗船在咖啡 “海洋” 中航行和争斗。强调特写头:使用特写镜头视角捕捉海盗船的动态和咖啡的纹理。展现争斗细爷:海盗船回的交火,船上海盗的动作。
Examples: 相似效果链接
Template:cssCopy Code
[场景描述] 在一杆充满就的杯子中,咖啡表面波动着仿佛一个微型的海洋。
[人物描述] 两艘装备精良的海盗船在这杯咖啡的海洋中航行,互相展开烈的争斗。
[目标] 透过逼真的特写镜头展现海盗船在咖啡杯子内互相争斗的壮场景。
[约束条件] 注意捕浞海盗的细节和动态,以及咖啡作为背景的纹理和波动 |
 | 一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克红色长裙和黑色子,拎黑色钱包。她戴着太阳墨镜涂着红色囗红。她走路自信又随意。街道潮湿且反光,在影色灯光的照射下形成镜面效果。许多行人走来走去。 | Context: 一条充满活力的东京街道在夜晚灯火通明,霓虹灯和动画广告牌交织成一道道流光溢彩的光带。细雨过后的街道湿润且反光,在多彩的灯光照射下形成迷人的镜面效果。许多行人在这灯光闪烁的夜色中来往匆匆。
Persona: 一位时尚女性身着黑色皮夹克,搭配鲜艳的红色长裙和黑色靴子,手拎一只黑色钱包。她戴着太阳镜,嘴唇涂抹着红色口红,走路自信又洒脱。
Goal: 展示这位时尚女性在霓虹灯光点缀的东京夜晚中自信与风采。
Constraints: 视觉应该突出夜晚的霓虹灯光效果,反映出潮湿街道的反光效果,以及人物的时尚装扮,强调人物的自信步伐和随性的走路风格。-
Steps::
1.设定场景为东京的一个夜晚街道,由霓虹灯照明。
2.描述人物:一位穿着黑色皮夹克、红色长裙和黑色靴子的时尚女性,手拿黑色钱包,戴着太阳镜并涂有红色口红。
3.强调人物的自信步伐和随性的走路风格。
4.描述环境:潮湿的街道在灯光下反射,周围有行人。示例: 提供一段描述或者图片,展示类似场景的效果。
Template:cssCopy Code:
[场景描述] 在一个充满活力的街道上,霓虹灯的彩光波动着,仿佛一个微型的夜晚海洋。
[人物描述] 一位时尚女性在这条街道上自信地行走,她的黑夹克和红裙在灯光下显得格外抢眼。
[目标] 通过鲜明的场景描述,展现时尚女性在霓虹灯光下的自信与风采。
[约束条件] 注重捕捉人物装扮的细节和动态,以及潮湿街道作为背景的纹理和反光。 |
5.Sora的出现以及AI的出现会对程序员产生什么影响呢
积极影响:
提高编程效率:AI工具可以自动化一些繁琐的编程任务,如代码检查、代码重构等,从而减少了程序员的工作量,提高了编程效率。同时,Sora文生视频也为程序员提供了更加高效和智能的视频开发工具,可以加快开发速度。
改善代码质量:AI工具可以帮助程序员发现代码中的缺陷和潜在问题,提高代码的质量和可靠性。这对于保证软件质量和用户体验至关重要。
促进编程教育:AI工具和Sora文生视频可以为编程初学者提供更加友好的编程环境和工具,使得编程教育更加容易上手和有趣,从而吸引更多的人加入编程领域。
提供更多创新机会:AI工具可以为程序员提供更多的灵感和创意,帮助他们创造出更加优秀的程序。同时,Sora文生视频也为程序员提供了更多的应用场景和市场需求,从而激发他们的创新热情。
负面影响:


6.Sora 技术原理全解析&小结
OpenAI 的研究论文《Video generation models as world simulators》探讨了在视频数据上进行大规模训练生成模型的方法。这项研究特别关注于文本条件扩散模型,这些模型同时在视频和图像上进行训练,处理不同时长、分辨率和宽高比的数据。研究中提到的最大模型 Sora 能够生成长达一分钟的高保真视频。以下是论文的一些关键点:
统一的视觉数据表示:研究者们将所有类型的视觉数据转换为统一的表示,以便进行大规模的生成模型训练。Sora 使用视觉补丁(patches)作为其表示方式,类似于大型语言模型(LLM)中的文本标记。
视频压缩网络:研究者们训练了一个网络,将原始视频压缩到一个低维潜在空间,并将其表示分解为时空补丁。Sora 在这个压缩的潜在空间中进行训练,并生成视频。
扩散模型:Sora 是一个扩散模型,它通过预测原始“干净”的补丁来从输入的噪声补丁中生成视频。扩散模型在语言建模、计算机视觉和图像生成等领域已经显示出了显著的扩展性。
视频生成的可扩展性:Sora 能够生成不同分辨率、时长和宽高比的视频,包括全高清视频。这种灵活性使得 Sora 能够直接为不同设备生成内容,或者在生成全分辨率视频之前快速原型化内容。
语言理解:为了训练文本到视频生成系统,需要大量的视频和相应的文本标题。研究者们应用了在 DALL·E 3 中引入的重新描述技术,首先训练一个高度描述性的标题生成器,然后为训练集中的所有视频生成文本标题。
图像和视频编辑:Sora 不仅能够基于文本提示生成视频,还可以基于现有图像或视频进行提示。这使得 Sora 能够执行广泛的图像和视频编辑任务,如创建完美循环的视频、动画静态图像、向前或向后扩展视频等。
模拟能力:当视频模型在大规模训练时,它们展现出了一些有趣的新兴能力,使得 Sora 能够模拟物理世界中的某些方面,如动态相机运动、长期一致性和对象持久性等。
尽管 Sora 展示了作为模拟器的潜力,但它仍然存在许多局限性,例如在模拟基本物理交互(如玻璃破碎)时的准确性不足。研究者们认为,继续扩展视频模型是开发物理和数字世界模拟器的有前途的道路。
这篇论文提供了对 Sora 模型的深入分析,展示了其在视频生成领域的潜力和挑战。通过这种方式,OpenAI 正在探索如何利用 AI 来更好地理解和模拟我们周围的世界。
本文作者:汀、人工智能,转自https://www.cnblogs.com/ting1/p/18023416
该文章在 2024/2/24 15:26:10 编辑过






 400 186 1886
400 186 1886


