用SQL清洗杂乱数据,以便开始进行分析。学习如何处理缺失值、重复记录、异常值等。
使用Segmind SSD-1B模型生成的图像
数据库表中的数据经常会很杂乱。你的数据可能包含缺失值、重复记录、异常值、不一致的数据输入等。因此,在使用SQL进行分析之前清洗数据是非常重要的。
当你学习SQL时,可以随意地创建数据库表,更改它们,根据需要更新和删除记录。但在实际操作中,几乎从不会这样。因为你可能没有权限更改表、更新和删除记录。但你有数据库的读取权限,可以运行大量的SELECT查询。
在本教程中,我们将创建一个数据库表,在其中填充记录,并了解如何使用SQL清洗数据。
创建带有记录的数据库表 在本教程中,让我们创建一个名为employees的员工表,如下所示:
-- 创建employees表 CREATE TABLE employees (INT PRIMARY KEY ,VARCHAR (50 ),DECIMAL (10 , 2 ),VARCHAR (20 ),VARCHAR (50 )接下来,让我们向表中插入一些虚构的样本记录:
-- 插入20个样本记录 INSERT INTO employees (employee_id, employee_name, salary, hire_date, department) VALUES 1 , 'Amy West' , 60000.00 , '2021-01-15' , 'HR' ),2 , 'Ivy Lee' , 75000.50 , '2020-05-22' , 'Sales' ),3 , 'joe smith' , 80000.75 , '2019-08-10' , 'Marketing' ), 4 , 'John White' , 90000.00 , '2020-11-05' , 'Finance' ),5 , 'Jane Hill' , 55000.25 , '2022-02-28' , 'IT' ),6 , 'Dave West' , 72000.00 , '2020-03-12' , 'Marketing' ),7 , 'Fanny Lee' , 85000.50 , '2018-06-25' , 'Sales' ),8 , 'Amy Smith' , 95000.25 , '2019-11-30' , 'Finance' ),9 , 'Ivy Hill' , 62000.75 , '2021-07-18' , 'IT' ),10 , 'Joe White' , 78000.00 , '2022-04-05' , 'Marketing' ),11 , 'John Lee' , 68000.50 , '2018-12-10' , 'HR' ),12 , 'Jane West' , 89000.25 , '2017-09-15' , 'Sales' ),13 , 'Dave Smith' , 60000.75 , '2022-01-08' , NULL ),14 , 'Fanny White' , 72000.00 , '2019-04-22' , 'IT' ),15 , 'Amy Hill' , 84000.50 , '2020-08-17' , 'Marketing' ),16 , 'Ivy West' , 92000.25 , '2021-02-03' , 'Finance' ),17 , 'Joe Lee' , 58000.75 , '2018-05-28' , 'IT' ),18 , 'John Smith' , 77000.00 , '2019-10-10' , 'HR' ),19 , 'Jane Hill' , 81000.50 , '2022-03-15' , 'Sales' ),20 , 'Dave White' , 70000.25 , '2017-12-20' , 'Marketing' );如果你能注意到的话,在这里使用了一小部分名字和姓氏作为样本,并为记录构建了姓名字段。不过,你也可以对记录进行更有创意的处理。
注意: 本教程中的所有查询都是针对MySQL的。但你可以自由选择使用你喜欢的关系型数据库管理系统(RDBMS)。
1. 缺失值 数据记录中的缺失值总是一个问题。因此,必须对其进行相应的处理。
一种简单的方法是删除包含一个或多个字段缺失值的所有记录。然而,除非你确定没有其他更好的处理缺失值的方法,否则不应该这样做。
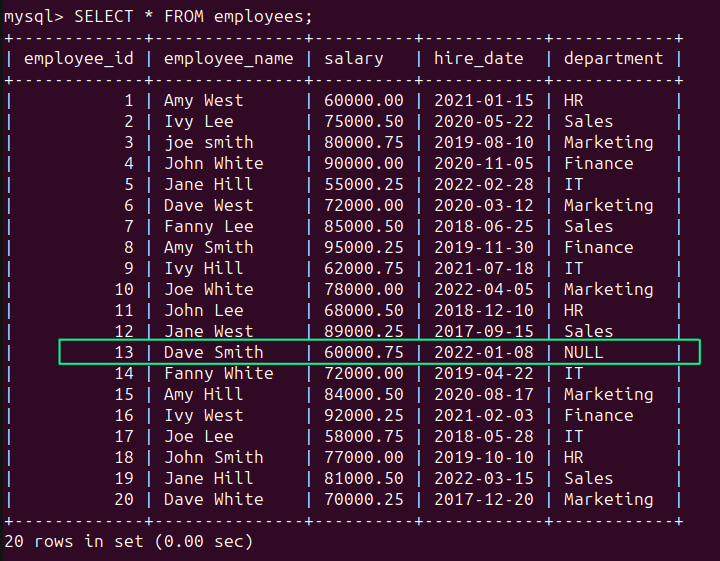
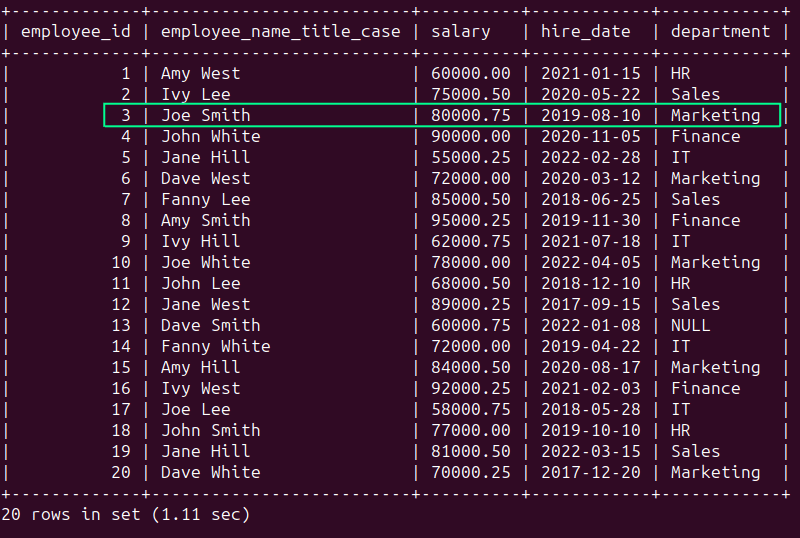
在employees表中,我们可以看到department列中有一个NULL值(参见employee_id为13的行),表示该字段缺失:
SELECT * FROM employees;
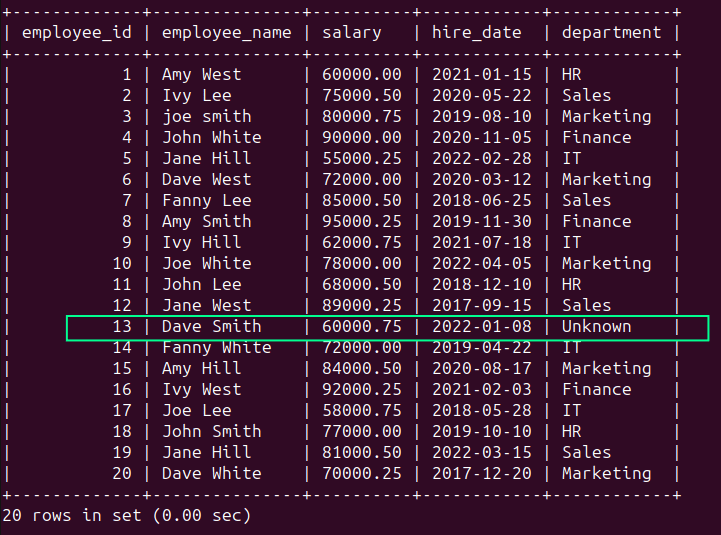
可以使用COALESCE()函数将NULL值替换为Unknown字符串:
SELECT COALESCE (department, 'Unknown' ) AS departmentFROM employees;运行上述查询应该会给出以下结果:
2. 重复记录 数据库表中的重复记录可能会扭曲分析结果。我们在数据库表中选择了employee_id作为主键,因此在employee_data表中不会有重复的员工记录。
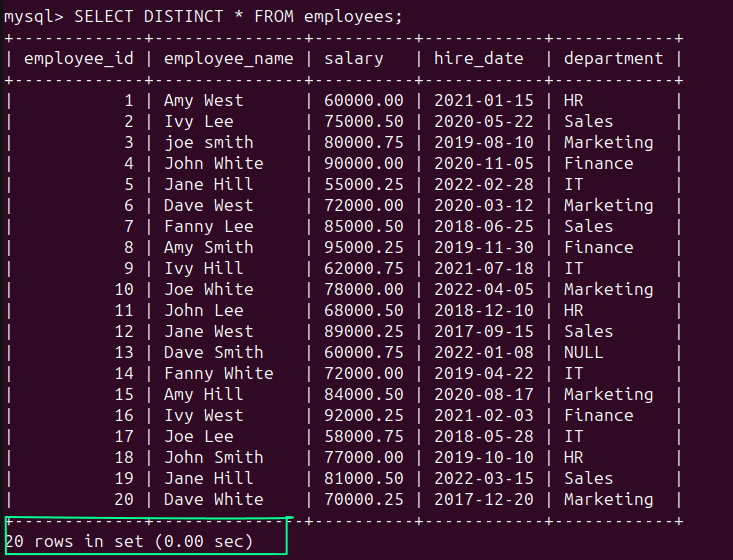
仍然可以使用SELECT DISTINCT语句:
SELECT DISTINCT * FROM employees;如预期所示,结果集包含了所有的20条记录:
3. 数据类型转换 可以注意到,hire_date列目前是VARCHAR类型,而不是日期类型。为了在处理日期时更方便,可以使用STR_TO_DATE()函数,如下所示:
SELECT STR_TO_DATE (hire_date, '%Y-%m-%d' ) AS hire_date,FROM employees;在这里,我们只选择了hire_date列,而没有对日期值执行任何操作。因此,查询的输出结果应与前一个查询的结果相同。
但是,如果你想执行诸如给值添加偏移日期之类的操作,那么该函数可能会有所帮助。
4. 异常值 一个或多个数值字段中的异常值可能会影响分析结果。因此,我们应该检查并清除异常值,以过滤掉不相关的数据。
但是,判断哪些值构成异常值需要领域知识,还需要利用领域知识和历史数据。
在我们的示例中,假设我们知道salary列的上限为100000。因此,salary列中的任何条目最多只能是100000。而大于此值的条目则是异常值。
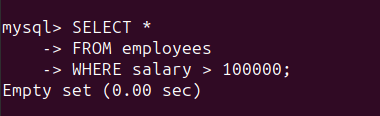
可以通过运行以下查询来检查这样的记录:
SELECT *FROM employeesWHERE salary > 100000 ;如图所示,salary列中的所有条目都是有效的。因此,结果集为空:
5. 数据输入不一致 数据输入和格式不一致的情况很常见,尤其是在日期和字符串列中。
在employees表中,可以看到员工joe smith对应的记录不是以标题大小写形式显示的。
但是,为了保持一致性,让我们选择所有以标题大小写格式显示的姓名。你需要将CONCAT()函数与UPPER()和SUBSTRING()函数结合使用,如下所示:
SELECT CONCAT (UPPER (SUBSTRING (employee_name, 1 , 1 )), -- Capitalize the first letter of the first name LOWER (SUBSTRING (employee_name, 2 , LOCATE (' ' , employee_name) - 2 )), -- Make the rest of the first name lowercase ' ' ,UPPER (SUBSTRING (employee_name, LOCATE (' ' , employee_name) + 1 , 1 )), -- Capitalize the first letter of the last name LOWER (SUBSTRING (employee_name, LOCATE (' ' , employee_name) + 2 )) -- Make the rest of the last name lowercase AS employee_name_title_case,FROM employees;
6. 验证范围 在谈论异常值时,我们提到希望对salary列设置上限为100000,并将任何超过100000的薪资条目视为异常值。
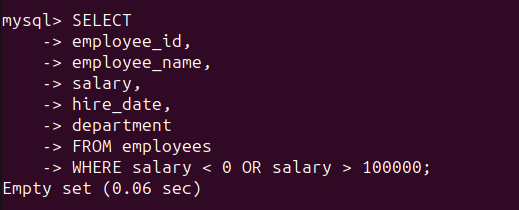
但同样也不能在salary列中有任何负值。因此,可以运行以下查询来验证所有员工记录的salary列值是否都在0和100000之间:
SELECT FROM employeesWHERE salary < 0 OR salary > 100000 ;如图所示,salary列值都在0和100000之间。因此,结果集为空:
7. 派生新列 派生新列本质上并不是数据清洗的步骤。然而,在实际操作中,你可能需要使用现有列派生出对分析更有帮助的新列。
例如,员工表包含一个hire_date列。更有帮助的字段可能是一个years_of_service列,表示员工在公司任职的年限。
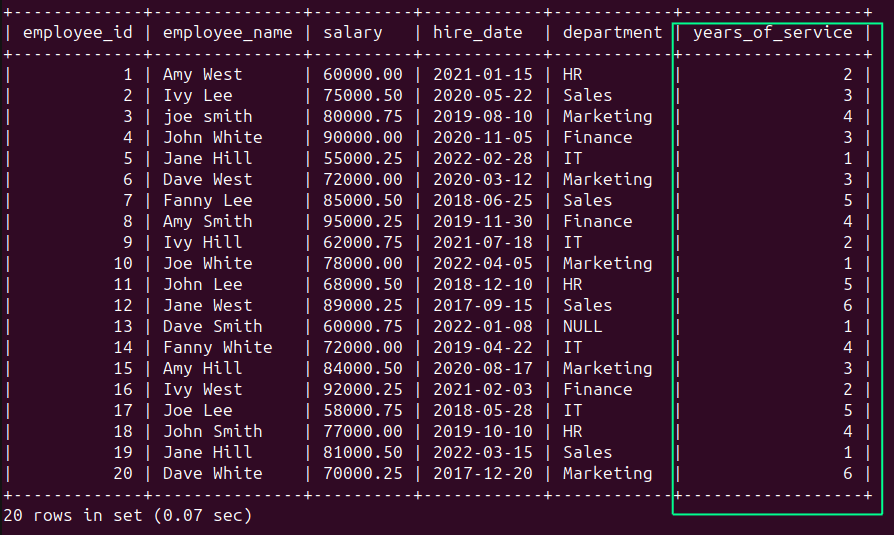
以下查询会计算当前年份与hire_date中年份值的差值,从而计算出years_of_service:
SELECT YEAR (CURDATE ()) - YEAR (hire_date) AS years_of_serviceFROM employees;应该会看到以下输出:
与我们运行的其他查询一样,这不会修改原始表。要向原始表中添加新列,需要拥有ALTER数据库表的权限。
总结 希望你理解了相关的数据清洗任务如何提高数据质量并促进更相关的分析。同时已经学会了如何检查缺失值、重复记录、不一致的格式、异常值等。
尝试创建自己的关系型数据库表,并运行一些查询来执行常见的数据清洗任务。






 400 186 1886
400 186 1886