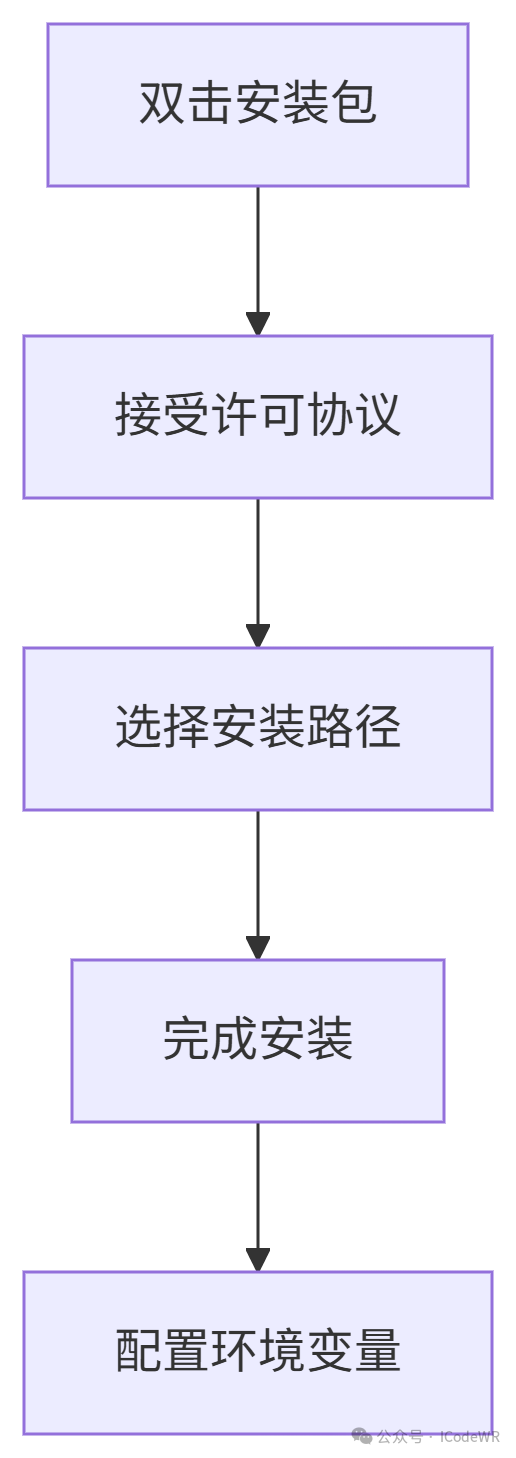
【WEB开发】wkhtmltox使用教程:HTML转PDF图片
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
|
基本语法:
wkhtmltopdf [选项] <输入文件/URL> <输出PDF文件>
示例:
# 将网页转换为PDF
wkhtmltopdf https://example.com output.pdf
# 将本地HTML文件转换为PDF
wkhtmltopdf input.html output.pdf
基本语法:
wkhtmltoimage [选项] <输入文件/URL> <输出图片文件>
示例:
# 将网页转换为PNG图片
wkhtmltoimage https://example.com output.png
# 指定图片质量
wkhtmltoimage --quality 85 input.html output.jpg
import subprocess
def html_to_pdf(html_path, pdf_path):
"""使用subprocess调用wkhtmltopdf"""
try:
subprocess.run(['wkhtmltopdf', html_path, pdf_path], check=True)
print(f"成功生成PDF: {pdf_path}")
except subprocess.CalledProcessError as e:
print(f"生成PDF失败: {e}")
# 使用示例
html_to_pdf('input.html', 'output.pdf')
import pdfkit
# 基本使用
pdfkit.from_url('http://example.com', 'output.pdf')
pdfkit.from_file('input.html', 'output.pdf')
pdfkit.from_string('<h1>Hello world!</h1>', 'output.pdf')
# 带配置选项
options = {
'page-size': 'A4',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'no-outline': None
}
pdfkit.from_url('http://example.com', 'output.pdf', options=options)
表2:wkhtmltopdf常用参数分类说明
options = {
'header-right': '[date]',
'footer-center': '第[page]页/共[topage]页',
'footer-font-size': '8',
'header-font-size': '8'
}
创建header.html:
<div style="text-align: right; font-size: 10px;">
报告日期: <span style="font-weight: bold;">[date]</span>
</div>
Python代码:
options = {
'header-html': 'header.html',
'footer-html': 'footer.html',
'margin-top': '25mm'
}
options = {
'toc': True, # 生成目录
'toc-header-text': '目录', # 目录标题
'toc-level-indentation': '2em', # 缩进
'toc-text-size-shrink': 0.8 # 字体缩小比例
}
pdfkit.from_file(['page1.html', 'page2.html'], 'combined.pdf')
# 或者使用命令行
# wkhtmltopdf page1.html page2.html combined.pdf
options = {
'cover': 'cover.html', # 封面页
'toc': True, # 目录
'cover-first': True # 封面放在第一页
}
禁用不必要的内容:
options = {
'no-images': None, # 不加载图片
'disable-javascript': None, # 禁用JS
'disable-smart-shrinking': None # 禁用智能缩放
}
使用Xvfb(Linux):
xvfb-run -a wkhtmltopdf input.html output.pdf
调整JavaScript延迟:
options = {
'javascript-delay': '1000' # 延迟1秒等待JS执行
}
pdfkit.from_url(url, output_path, options=None, configuration=None)
pdfkit.from_file(input, output_path, options=None, configuration=None)
pdfkit.from_string(input, output_path, options=None, configuration=None)
# 自定义wkhtmltopdf路径
config = pdfkit.configuration(wkhtmltopdf='/usr/local/bin/wkhtmltopdf')
# 使用配置
pdfkit.from_string(html, 'output.pdf', configuration=config)
from jinja2 import Template
import pdfkit
# 准备数据
report_data = {
'title': '销售报告',
'date': '2023-11-15',
'items': [
{'name': '产品A', 'sales': 1200},
{'name': '产品B', 'sales': 1800}
]
}
# 加载模板
withopen('report_template.html') as f:
template = Template(f.read())
# 渲染HTML
html_content = template.render(report_data)
# 生成PDF
pdfkit.from_string(html_content, 'sales_report.pdf', options={
'encoding': "UTF-8",
'margin-top': '0.5in',
'margin-bottom': '0.5in'
})
import asyncio
import aiofiles
from concurrent.futures import ThreadPoolExecutor
asyncdefgenerate_pdf(html_path, pdf_path):
asyncwith aiofiles.open(html_path, 'r') as f:
html = await f.read()
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as pool:
await loop.run_in_executor(
pool,
lambda: pdfkit.from_string(html, pdf_path)
)
print(f"Generated: {pdf_path}")
asyncdefmain():
tasks = [
generate_pdf(f'input_{i}.html', f'output_{i}.pdf')
for i inrange(1, 6)
]
await asyncio.gather(*tasks)
asyncio.run(main())
解决方案:
# Ubuntu
sudo apt-get install fonts-wqy-microhei
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
options = {
'encoding': "UTF-8",
'user-style-sheet': '/path/to/stylesheet.css'
}
解决方案:
options = {
'disable-smart-shrinking': None, # 禁用智能缩放
'viewport-size': '1280x1024', # 设置视口大小
'dpi': 300, # 提高DPI
'zoom': 0.8 # 适当缩放
}
表3:性能问题排查表
# views.py
from django.http import HttpResponse
import pdfkit
defgenerate_pdf(request):
# 获取或生成HTML
html = "<h1>Django PDF 报告</h1>"
# 生成PDF
pdf = pdfkit.from_string(html, False, options={
'encoding': "UTF-8"
})
# 创建响应
response = HttpResponse(pdf, content_type='application/pdf')
response['Content-Disposition'] = 'attachment; filename="report.pdf"'
return response
from flask import Flask, make_response
import pdfkit
app = Flask(__name__)
@app.route('/report')
def generate_report():
html = render_template('report.html')
pdf = pdfkit.from_string(html, False)
response = make_response(pdf)
response.headers['Content-Type'] = 'application/pdf'
response.headers['Content-Disposition'] = 'inline; filename=report.pdf'
return response
import smtplib
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
import pdfkit
defsend_report_by_email(recipient, html_content):
# 生成PDF
pdf = pdfkit.from_string(html_content, False)
# 创建邮件
msg = MIMEMultipart()
msg['Subject'] = '每日报告'
msg['From'] = 'reports@company.com'
msg['To'] = recipient
# 添加PDF附件
part = MIMEApplication(pdf, Name='report.pdf')
part['Content-Disposition'] = 'attachment; filename="report.pdf"'
msg.attach(part)
# 发送邮件
with smtplib.SMTP('smtp.company.com') as server:
server.send_message(msg)
import pandas as pd
import pdfkit
# 生成数据分析报告
defgenerate_analysis_report(data_path):
# 读取数据
df = pd.read_csv(data_path)
# 生成HTML
html = """
<h1>数据分析报告</h1>
<h2>数据概览</h2>
{}
<h2>描述统计</h2>
{}
""".format(
df.head().to_html(),
df.describe().to_html()
)
# 生成PDF
pdfkit.from_string(html, 'analysis_report.pdf', options={
'encoding': 'UTF-8',
'margin-top': '0.5in'
})

初级阶段:
中级阶段:
高级阶段:
官方文档:
学习资源:
相关工具:
阅读原文:原文链接






 400 186 1886
400 186 1886